Object detection is an essential task in computer vision and plays a crucial role in many real-world applications. With the help of AI tools, object detection has become more accurate and efficient than ever before. There are several AI tools available for object detection, each with its own unique strengths and weaknesses.
In this blog, we will explore the best AI tools for object detection, including open-source libraries like TensorFlow and PyTorch, as well as cloud-based services like Amazon Rekognition and Google Cloud Vision API. We will discuss their features, advantages, and limitations, and provide insights on how to choose the best tool for your specific use case. Whether you are a developer, business, or researcher, understanding the different options available for object detection can help you improve the accuracy and efficiency of your applications.
TensorFlow Object Detection API

The TensorFlow Object Detection API is a powerful AI tool that facilitates object detection and recognition in images and videos. It provides a vast library of pre-trained models that can be fine-tuned and customized as per the specific needs of the project. The API is open-source, easy to use, and supports both CPU and GPU acceleration, making it a popular choice among researchers and developers. Additionally, it supports a variety of machine learning models, including Single Shot Detector (SSD), Faster R-CNN, and Mask R-CNN, allowing users to choose the model that best suits their requirements. The TensorFlow Object Detection API also includes powerful features like transfer learning, data augmentation, and visualizing the training process, which makes it an ideal choice for both beginners and advanced users.
Pros
Cons
Overall Rank
YOLO (You Only Look Once)
.png)
YOLO, which stands for You Only Look Once, is a state-of-the-art object detection algorithm that uses a single neural network to detect objects in real-time. YOLO divides an image into a grid and predicts the bounding boxes and class probabilities for each grid cell. The network then outputs a set of bounding boxes, each with a class probability, and the confidence that the bounding box actually contains an object. YOLO has several advantages over other object detection algorithms, including its ability to detect objects in real-time, its high accuracy, and its ability to generalize well to new objects and scenes. Additionally, YOLO can be easily trained on new datasets, making it a versatile tool for a variety of computer vision applications.
Pros
Cons
Overall Rank
Mask R-CNN

Mask R-CNN is an advanced AI tool that combines object detection and instance segmentation to accurately identify and segment objects within an image or video. The model uses a two-stage architecture that first identifies object proposals and then refines them to generate accurate instance masks. With the ability to detect and segment multiple objects within a single image, Mask R-CNN has proven to be a highly effective tool for a variety of applications, including object tracking, image and video editing, and even autonomous vehicles.
Pros
Cons
Overall Rank
Detectron2

Detectron2 is an advanced open-source computer vision library powered by PyTorch, designed to help researchers and developers build and deploy state-of-the-art computer vision models. With its modular architecture and intuitive APIs, Detectron2 enables users to easily customize and train models for object detection, instance segmentation, keypoint detection, and more. It comes with a large collection of pre-trained models and supports a wide range of datasets and annotations formats, making it a versatile tool for various computer vision applications. Moreover, Detectron2 has a highly optimized and parallelized codebase, which enables it to achieve impressive inference and training performance on large-scale datasets.
Pros
Cons
Overall Rank
OpenCV

OpenCV AI tool is a powerful computer vision library that provides developers with a wide range of tools and algorithms for real-time image processing, object detection, recognition, and tracking. It is an open-source library that supports multiple programming languages such as Python, C++, and Java, making it accessible to a large community of developers. OpenCV AI tool offers features such as facial recognition, object detection, and tracking, as well as the ability to create 3D models from 2D images and videos. The library is constantly updated and improved, making it a reliable and efficient tool for computer vision applications.
Pros
Cons
Overall Rank
Caffe

Caffe is a deep learning framework that allows developers to build, train, and deploy convolutional neural networks for image classification, segmentation, and other computer vision tasks. It is an open-source project developed by the Berkeley Vision and Learning Center (BVLC) and has gained popularity due to its high efficiency, modularity, and extensibility. Caffe's modular design makes it easy to add new layers, optimizers, and loss functions, making it a versatile tool for deep learning researchers and practitioners. It also has a large community of contributors who continue to develop new features and improve its performance. With Caffe, developers can quickly prototype and experiment with different deep learning architectures and achieve state-of-the-art results.
Pros
Cons
Overall Rank
MXNet

MXNet is an open-source deep learning framework that provides a scalable and flexible platform for developing and deploying machine learning models. It supports various programming languages, including Python, R, Scala, and C++, which makes it accessible to a wide range of users. MXNet offers efficient computation on both CPUs and GPUs, which makes it suitable for building large-scale models that require parallel processing. Additionally, MXNet offers a high-level interface that allows users to quickly prototype and experiment with different models, as well as a low-level interface that gives users complete control over the model architecture and training process. Overall, MXNet is a powerful tool that offers a great balance between ease of use and flexibility, making it an excellent choice for both beginners and advanced users.
Pros
Cons
Overall Rank
Darknet
Darknet AI tools are sophisticated software programs designed to operate within the dark web and provide an extra layer of anonymity to users. These tools are particularly useful for those who wish to remain hidden from the authorities or engage in illicit activities. Darknet AI tools use artificial intelligence algorithms to mask user activity and encrypt communications, making it almost impossible for law enforcement agencies to trace their actions. These tools are not only used by cybercriminals but also by journalists and activists who operate in oppressive regimes where their safety may be compromised.
Pros
Cons
Overall Rank
Haar Cascade Classifier
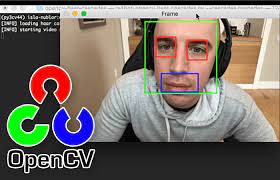
Haar Cascade Classifier is a computer vision algorithm that is used to detect objects in images or videos by analyzing their features. It was developed by Viola and Jones in 2001 and has been widely used in various applications such as facial recognition, object detection, and tracking. The algorithm works by scanning an image and identifying areas that contain certain features that match the features of the object being searched for. These features are defined using mathematical models known as Haar features. The Haar Cascade Classifier is known for its high accuracy, speed, and efficiency, making it a popular tool in the field of computer vision.
Pros
Cons
Overall Rank
Hugging Face Transformers

Hugging Face Transformers is an advanced AI tool that has revolutionized the field of natural language processing. It allows users to easily create, train and deploy state-of-the-art models for various NLP tasks, including text classification, named entity recognition, machine translation, and question-answering systems. The tool offers a wide range of pre-trained models that can be fine-tuned on specific tasks with a few lines of code, making it accessible to users with limited coding experience. Hugging Face Transformers also provides an interactive platform for users to share their models, collaborate with others, and explore new models developed by the community. Overall, it is a powerful and versatile tool that has made NLP accessible to a wider range of users.
Pros
Cons
Overall Rank
Clarifai

Clarifai is an AI tool that specializes in computer vision, providing advanced image and video recognition services to businesses. The platform leverages machine learning algorithms to identify objects, scenes, and faces within visual content with high accuracy. Additionally, Clarifai can detect explicit or violent content, moderate user-generated content, and classify images and videos by custom-defined categories. With its user-friendly interface and extensive documentation, Clarifai is a valuable resource for businesses looking to incorporate AI-powered visual recognition technology into their workflows.
Pros
Cons
Overall Rank
Google Cloud Vision API

Google Cloud Vision API is an artificial intelligence tool that enables developers to build applications that can understand the content of images. This tool utilizes machine learning models to analyze images and extract information such as labels, faces, logos, and text from them. It also has the ability to detect inappropriate content and recognize landmarks, which makes it useful for a wide range of applications such as image classification, search, and organization. The Cloud Vision API provides a user-friendly interface that allows developers to easily integrate image recognition capabilities into their applications, making it a powerful tool for businesses that want to leverage the benefits of AI.
Pros
Cons
Overall Rank
Amazon Rekognition

Amazon Rekognition is an artificial intelligence tool developed by Amazon Web Services (AWS) that provides facial and image recognition capabilities to businesses. It can detect, analyze and match faces in images and videos, recognize objects and scenes within images, and extract text from images and videos. Amazon Rekognition is a powerful tool that can be integrated into various applications, including security systems, marketing campaigns, and social media platforms. It has the potential to revolutionize the way businesses operate, by providing them with valuable insights into customer behavior, preferences, and demographics. Moreover, it can improve security and prevent fraud, by identifying potential threats and suspicious behavior.
Pros
Cons
Overall Rank
Microsoft Azure Cognitive Services

Microsoft Azure Cognitive Services is an AI tool that provides a broad range of pre-built algorithms and APIs to help developers integrate intelligent features into their applications. With Azure Cognitive Services, developers can easily add powerful functionalities such as speech recognition, image analysis, natural language processing, and more without requiring extensive knowledge of machine learning. Azure Cognitive Services is a cloud-based platform that offers high scalability, reliability, and security, enabling developers to build intelligent applications that can learn and adapt to user needs over time. Furthermore, Azure Cognitive Services offers a pay-as-you-go pricing model that allows developers to only pay for the specific features they use, making it a cost-effective solution for businesses of all sizes.
Pros
Cons
Overall Rank
IBM Watson Visual Recognition

IBM Watson Visual Recognition is an AI-powered tool that can analyze and interpret images and videos to identify objects, faces, text, and other visual elements. It can classify images into predefined categories or custom classifiers based on user-defined criteria, and also provide confidence scores for each classification. With its advanced machine learning algorithms, Watson Visual Recognition can continuously learn and improve its accuracy over time, making it a valuable asset for a wide range of applications, including social media monitoring, product quality control, and security surveillance. Additionally, it provides developers with an easy-to-use API for integrating visual recognition capabilities into their own applications.
Pros
Cons
Overall Rank
Intel OpenVINO

Intel OpenVINO (Open Visual Inference and Neural Network Optimization) is an AI toolkit that allows developers to deploy pre-trained deep learning models across various hardware platforms. OpenVINO enables efficient and fast inference of computer vision and natural language processing models on CPUs, GPUs, and other hardware accelerators, making it easier to develop and deploy AI applications. It also offers model optimization techniques such as quantization, pruning, and compression, which can significantly reduce the memory footprint and computational requirements of deep learning models without compromising their accuracy. With its support for popular deep learning frameworks like TensorFlow, PyTorch, and Caffe, OpenVINO has become a go-to tool for developers who want to build and deploy scalable and efficient AI applications across a range of devices and edge deployments.
Pros
Cons
Overall Rank
Fast R-CNN
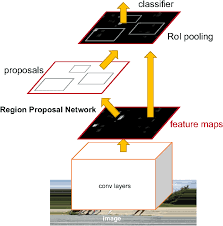
Fast R-CNN is a powerful object detection tool that uses convolutional neural networks (CNNs) to classify and localize objects within an image. It builds on the previous version of the tool, R-CNN, by streamlining the training process and improving detection accuracy. Fast R-CNN uses a single network to both propose object regions and classify them, rather than the two separate networks used in R-CNN. This reduces the overall training time and improves accuracy by allowing the network to share features between the two tasks. Additionally, Fast R-CNN introduces a new layer called the RoI pooling layer, which allows the network to efficiently process object proposals of different sizes and shapes. Overall, Fast R-CNN is a highly effective object detection tool that has been widely used in various applications, from self-driving cars to medical imaging.
Pros
Cons
Overall Rank
RetinaNet

RetinaNet is an AI tool that has been developed for object detection in images. It is a single-shot detector that is based on a feature pyramid network architecture and uses a novel focal loss function. The architecture of RetinaNet enables it to detect objects of varying scales and aspect ratios within an image. The use of focal loss function further improves the accuracy of the model by addressing the class imbalance problem that is common in object detection tasks. With its high accuracy and efficiency, RetinaNet has become a popular choice for various computer vision applications such as self-driving cars, facial recognition, and surveillance systems.
Pros
Cons
Overall Rank
In conclusion, the field of AI has made great strides in recent years, especially in the area of object detection. There are several AI tools available for object detection that can be used by developers, businesses, and researchers alike. From open-source libraries like TensorFlow and PyTorch to cloud-based services like Amazon Rekognition and Google Cloud Vision API, there is no shortage of options for those looking to integrate object detection into their applications. Each tool has its own strengths and weaknesses, and choosing the right one depends on the specific needs of the project. Some may prioritize accuracy and precision, while others may prioritize speed and scalability. However, one thing is certain
