Artificial intelligence has revolutionized the way we create and interact with visual media. One of the most exciting developments in this field is the emergence of AI image generators. These powerful tools use machine learning algorithms and neural networks to create stunning, high-quality images with minimal effort. From photorealistic landscapes to abstract art, AI image generators have become a go-to resource for artists, designers, and photographers who want to explore new possibilities and push the boundaries of visual creativity.
In this blog, we will explore some of the best AI image generators available today. Whether you're a seasoned pro or just getting started with visual art, these tools offer a wealth of exciting features and capabilities that can help you take your work to the next level. From deep learning algorithms that can generate entirely new images to neural style transfer techniques that can apply the characteristics of one image to another, the world of AI image generation is full of amazing possibilities. So let's dive in and discover some of the most impressive tools and techniques for creating stunning images with the help of artificial intelligence.
DALL-E

DALL-E is an AI-powered image generator developed by OpenAI that can create highly realistic images from textual descriptions. Unlike traditional image generators that use pre-existing templates, DALL-E generates images from scratch by combining various visual elements in a creative way. The model can generate a wide range of images, from simple objects to complex scenes with multiple objects and backgrounds. DALL-E is trained on a large dataset of images and text, and uses a transformer-based architecture similar to GPT-3.
Pros
Cons
Overall Rank
StyleGAN

StyleGAN is a type of generative adversarial network (GAN) that uses deep learning to generate high-quality, realistic images. Unlike traditional GANs that generate images pixel-by-pixel, StyleGAN generates images by using a hierarchical approach, where it first generates coarse features and then adds more details at each subsequent layer. This method allows for more control over the final output and produces images that are not only realistic but also highly diverse and unique. StyleGAN has been used in a wide range of applications, from generating realistic images of faces and landscapes to creating new styles of clothing and furniture.
Pros
Cons
Overall Rank
GPT-3

GPT-3, or Generative Pre-trained Transformer 3, is a highly advanced artificial intelligence language model developed by OpenAI. With over 175 billion parameters, it is the largest language model ever created and has the capability to generate human-like language, complete tasks such as translation and summarization, and even write creative content like poetry and music. Its abilities have revolutionized the field of natural language processing and have enormous potential for a wide range of applications, from improving customer service chatbots to aiding in scientific research and discovery.
Pros
Cons
Overall Rank
BigGAN

BigGAN is a state-of-the-art generative model developed by researchers at Google Brain, which has achieved unprecedented performance in generating high-resolution images that closely resemble real-world photographs. The architecture of BigGAN consists of a generator network that generates images from random noise vectors, and a discriminator network that discriminates between real and fake images. What makes BigGAN stand out from other generative models is its ability to generate images with high-fidelity details and diverse semantic variations, which can be controlled by modifying the input noise vectors. BigGAN has been trained on a large-scale dataset of natural images, and has shown remarkable results in a variety of tasks, including image synthesis, data augmentation, and few-shot learning.
Pros
Cons
Overall Rank
CycleGAN

CycleGAN is a deep learning model that can learn to translate images from one domain to another without requiring paired examples. It uses a cycle-consistent adversarial loss to ensure that the translated image can be reconstructed back to the original domain, which enables the model to capture the semantic content of the images. CycleGAN has been successfully applied to a variety of image-to-image translation tasks, such as transforming photos into paintings, turning horses into zebras, and converting day scenes into night scenes. The model has also been extended to handle multiple domains, enabling the translation of images across more than two domains. CycleGAN is a powerful tool for generating novel images and has applications in areas such as computer vision, graphics, and art.
Pros
Cons
Overall Rank
Deep Dream

Deep Dream is a fascinating image generation technique that utilizes artificial neural networks to produce surreal and dreamlike visuals. It was developed by Google in 2015, and since then, it has become a popular tool for artists and researchers alike. Deep Dream works by taking an existing image and applying a neural network algorithm that enhances certain patterns and features within the image while suppressing others. This process is repeated multiple times, resulting in a final image that is a bizarre and distorted version of the original. The results can be both beautiful and unsettling, and they offer a glimpse into the inner workings of artificial intelligence and the human mind.
Pros
Cons
Overall Rank
ESRGAN

ESRGAN, short for Enhanced Super-Resolution Generative Adversarial Networks, is an advanced image upscaling algorithm that uses machine learning techniques to generate high-resolution images. The main feature of ESRGAN is its ability to produce more detailed and visually appealing images than traditional upscaling methods. The algorithm is trained on a large dataset of high-resolution images, allowing it to learn and generate better-quality images. ESRGAN uses a two-step process where it first generates a low-resolution image and then uses a discriminator network to evaluate and improve the quality of the output. The algorithm has shown impressive results in generating realistic textures and patterns in images, making it an important tool for various applications in the fields of computer graphics, digital photography, and video processing.
Pros
Cons
Overall Rank
ProGAN

Progressive Growing of GANs (ProGAN) is a type of generative adversarial network (GAN) that is capable of generating high-quality, high-resolution images. Unlike traditional GANs that generate low-resolution images and then try to scale them up, ProGAN generates high-resolution images from the very beginning. The key to its success is its progressive training approach, where the network is trained in a stepwise manner, starting from low resolution and gradually increasing the resolution over time. This approach allows the network to learn more complex features and textures at higher resolutions, resulting in highly realistic images. ProGAN has been used to generate realistic images of faces, landscapes, and even galaxies, and has the potential to revolutionize the fields of art, design, and entertainment.
Pros
Cons
Overall Rank
GauGAN
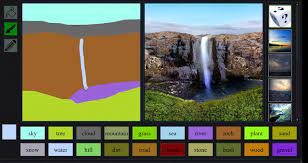
GauGAN is an AI-powered image creation tool developed by Nvidia that allows users to generate realistic landscapes, scenes, and objects using simple brushstrokes. The tool uses a deep learning algorithm to understand and replicate the natural elements that make up a scene, such as trees, water, and clouds, based on the user's input. With GauGAN, users can quickly and easily create high-quality images for a variety of purposes, from artistic expression to design and architecture.
Pros
Cons
Overall Rank
VQGAN

VQGAN (Vector Quantized Generative Adversarial Networks) is an AI model that can generate high-quality images from textual descriptions or even sketches. It works by learning the distribution of images in a large dataset and then using that knowledge to create new, unique images. What sets VQGAN apart from other generative models is its ability to control the style and content of the generated images through specific prompts or conditioning inputs. With VQGAN, users can create images that are surreal, photorealistic, abstract, or anything in between. The possibilities are endless, making it a valuable tool for artists, designers, and other creatives.
Pros
Cons
Overall Rank
AttnGAN
AttnGAN, short for Attentional Generative Adversarial Network, is a state-of-the-art image generation model that uses attention mechanisms to generate high-quality images from textual descriptions. The model is based on the GAN architecture and consists of a generator network and a discriminator network that work together to generate realistic images. The attention mechanism allows the generator to focus on specific parts of the text description while generating the corresponding image, resulting in images with fine details and high visual quality. AttnGAN has shown impressive results in various image generation tasks, including generating images of birds, flowers, and animals, among others. The model has also been used in applications such as image captioning and image editing, where it has demonstrated its ability to generate high-quality images that closely match the input textual description.
Pros
Cons
Overall Rank
PixelRNN
![]()
PixelRNN is a deep neural network architecture that generates realistic images by modeling the probability distribution of each pixel given its preceding pixels. This is achieved through a recurrent neural network (RNN) that sequentially predicts the probability distribution of each pixel based on its previous pixels. PixelRNN has been successful in generating images that closely resemble natural images, such as handwritten digits and faces. By using a more complex architecture, PixelRNN can capture the dependencies between pixels and generate images with higher resolution and diversity. Overall, PixelRNN is a powerful tool for image generation and has significant potential for various applications such as computer vision, graphics, and art.
Pros
Cons
Overall Rank
StackGAN
StackGAN is a generative adversarial network architecture that aims to generate high-resolution images from textual descriptions. The model consists of two stages
Pros
Cons
Overall Rank
Wav2Pix

Wav2Pix is a fascinating AI technology that can generate realistic images from audio inputs. By training a deep neural network on paired audio-visual data, Wav2Pix can predict the corresponding image that matches a given audio clip, even if the image has never been seen before. This technology has the potential to revolutionize a variety of fields, from film and video game production to assistive technology for the visually impaired. Wav2Pix could enable individuals with hearing impairments to "see" the content of videos, while also allowing artists and designers to generate images based on audio cues, opening up new possibilities for creative expression.
Pros
Cons
Overall Rank
DCGAN

Deep Convolutional Generative Adversarial Networks (DCGAN) is a type of neural network architecture designed to generate new data that is similar to the training dataset. DCGANs consist of a generator and a discriminator network, where the generator learns to create realistic data samples from random noise, and the discriminator learns to distinguish between real and fake data. DCGANs have been successfully used in various applications, such as image and text generation. One of the strengths of DCGAN is its ability to learn and represent complex high-dimensional distributions, allowing it to generate high-quality images with details and textures that are difficult to replicate using other methods.
Pros
Cons
Overall Rank
Image-to-Image Translation

Image-to-image translation is a subfield of computer vision that involves the transformation of an image from one domain to another. The goal of this technique is to learn a mapping function that can translate an input image from a source domain to an output image in a target domain while preserving the underlying structure and content of the original image. This technique has been successfully applied in a wide range of applications such as style transfer, image colorization, and image super-resolution. One of the key challenges in image-to-image translation is to preserve the semantic content of the image while making the desired changes. This requires the use of sophisticated deep learning models such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) that can learn complex mappings between image domains.
Pros
Cons
Overall Rank
Neural Style Transfer

Neural style transfer is a fascinating technique that allows for the creation of visually appealing images by combining the style of one image with the content of another. It utilizes deep neural networks to learn the features of the content and style images and then generates a new image that blends both. This process enables users to transform ordinary images into works of art that mimic the style of famous artists or generate unique visual styles. Neural style transfer has been applied in various domains, such as fashion design, video production, and game development. Its potential is not limited to the artistic realm, as it can also be used for medical imaging, satellite imagery analysis, and more.
Pros
Cons
Overall Rank
In conclusion, AI image generators have come a long way in recent years, and there are now many excellent options available for creating stunning, high-quality images with minimal effort. Whether you're a professional designer, an amateur photographer, or simply someone who enjoys creating visual art, there's an AI image generator out there that can help you achieve your creative goals. From the popular and versatile StyleGAN2, which can create highly realistic and varied images with ease, to the more specialized tools like GauGAN, which is designed specifically for generating photorealistic landscapes and scenery, the range of AI image generators available is truly impressive. One of the most exciting things about AI image generators is that they are constantly improving and evolving, with new algorithms and techniques being developed all the time. As these tools become more advanced and sophisticated, we can expect to see even more amazing and innovative applications of AI in the world of visual art. Overall, the rise of AI image generators is an exciting development for anyone interested in creating or working with visual media. By harnessing the power of machine learning and neural networks, these tools offer a new level of convenience and creative potential that was once unimaginable. Whether you're a professional artist or just someone who loves to experiment with visuals, AI image generators are definitely worth exploring.
